Article at a Glance:
- A brief intro to Django 3
- Which parts you might encounter as a data scientist?
- How-to run Migration with a step-by-step guide and sample code
- How-to run Django Query if you know SQL
Who is it for: data scientists who want to plug your code into your organization’s codebase, which was based on Django.
Before I start to share what I’ve learned about Django 3, I’d like to mention why I needed to learn Django quickly. I work for a company called Outside and my primary focus has been building recommender systems to personalize users’ content consumption. Two months ago, we decided to change the web development framework from FastAPI to Django. I had very limited knowledge about FastAPI before we started the project and I learned just enough to successfully implement the data science algorithm part. But with the new changes, I need to evolve quickly to migrate my code into the Django framework.
Sidenote: as a data scientist, you’ve probably seen and agonized about the famous Data Science Venn Diagram, in which you need to be well versed in math & stats, computer science, and domain expertise, especially so if you want to be a unicorn 🦄. In my personal career development, I noticed that my jobs require me to expand my skills in mainly two areas, besides deepening data science and machine learning knowledge:
- Web Development: if you work for a startup that builds consumer-facing apps (web and/or mobile), it’s likely that you will get exposed to the question — how can we deploy data science models to apps? How to wrap models in APIs? Wait, what’s the difference between REST API vs GraphQL? What are Apollo and federated data? In fact, those are all the questions I need to figure out in order to integrate my code into the larger organization’s codebase.
- Data Engineering: it’s likely that your organization will have dedicated data engineers to handle the production database, but you will never regret expanding your skillset by including design tables, database migrations, getting very familiar with how to connect Snowflake, Postgres and Redshift to PyCharm and Jupyter Notebook.
All right, enough background story and let’s get started on Django.
A brief intro to Django 3
One-liner explanation: Django 3 is a python web development framework.
What is a web framework? I made this diagram to illustrate the Django Model View Template (MTV) paradigm.
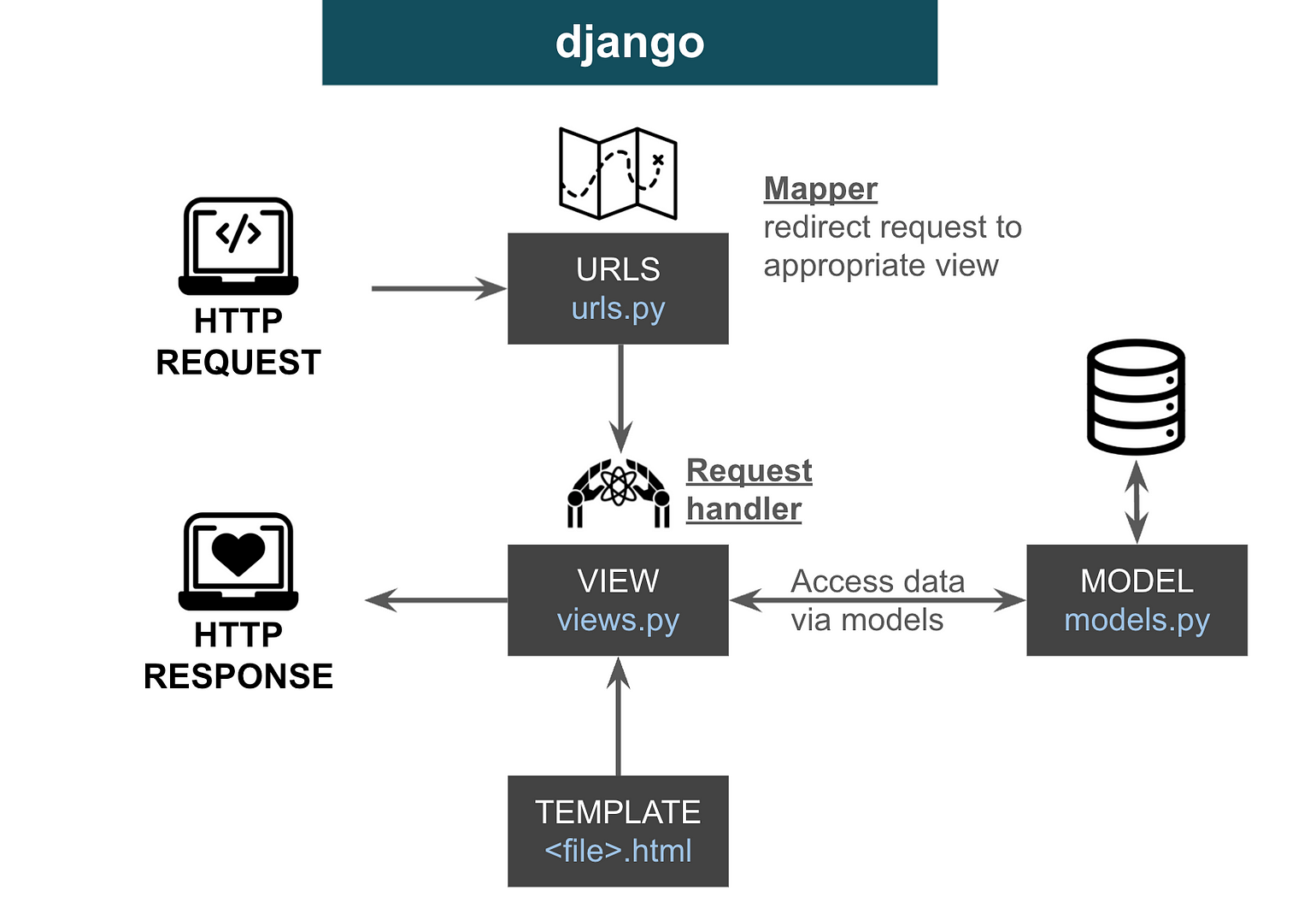
Basically, a client sent an HTTP request, and it gets passed to urls.py , which helps to map the request to the appropriate view. views.py is like a request handle, it can access data and organize the data in the right way using a template, and then send it back as an HTTP response.
That’s all we need to know and I told you it’ll be “brief” .🍃
Let’s move to the more interesting question →
Which parts you might encounter as a data scientist?
From my personal experience, it is very likely you will need to know how to proper insert your code into models.py which allows you to specify the schema of the data and write customized functions within the data model class.
For example, below is a data class called ContentItem, and just like we start with schema design with table creation in SQL, we define a class with the expected data type for each column or data field.
A couple of things worth noting:
- If you don’t create a
idcolumn, Django will automatically add that to the actual table - If you want to create a list for column
tags, for example, store sth like [news, cycling, winter] in one cell, you can useArrayField,models.CharFieldmeans that inside the list, each element is a string. - Data fields in Django follow very SQL-like column constraints.
Column Constraints are the rules applied to the values of individual columns:
PRIMARY KEYconstraint can be used to uniquely identify the row.
UNIQUEcolumns have a different value for every row.
NOT NULLcolumns must have a value.
DEFAULTassigns a default value for the column when no value is specified.
There can be only one PRIMARY KEY column per table and multiple UNIQUE columns. For example, when we created the ContentItem class in Django, the auto-generated id will become the PRIMARY KEY column and we have both item_url and item_uuid specified as UNIQUE columns.
Once you have the data model class, you need to run data migration to apply the schema to the new table.
How-to run Migrations in Django?
Step 1: Assume you are in the same project environment, open Pycharm terminal, and run
$ python manage.py makemigrations
Then a new migration file will be automatically populated similar to 0018_auto_...py , since there are already 17 migrations existed, mine is denoted as 0018 . Generally, you don’t have to edit anything in this file.
Step2: apply the migration file to your database by running
$ python manage.py migrate
More details can be found in Django’s official documentation.
How-to run Django Query if you know SQL
For most data scientists, luckily we know SQL. And Amit Chaudhary wrote a wonderful post about how to perform our typical SQL tasks in Django.
Since he beat me to write this first, I’ll add a thing to watch out for: be careful about when are QuerySets evaluated (From book <Django 3 By Example> Chapter 1):
“ QuerySets are only evaluated in the following cases:
– The first time you iterate over them
– When you slice them, for instance,
objects.all()[:3]– When you pickle or cache them
– When you call
repr()orlen()on them– When you explicitly call
list()on them”
This will become very relevant if you want to use the output of QuerySet in your function.
There’s also another great medium post if you want to learn more about Django ORM.
Closing Thoughts
- Django is a powerful tool for web development. And as data scientists, we can expand in two directions: Frontend ← Data Science → Backend. Learning Django can strengthen our knowledge on both Frontend and Backend. Examples in this post are more related to Backend, but in real-life situations, after adding tables and migrations, I would also need to create customized functions and update the resolver in the frontend API — GraphQL.
- A typical refactor workflow I found myself using is: update
models.py→ run migrations → run data ingestion task → updateschema.graphql→ update the resolver function ingraphql.py - My understanding of Django is still very limited, and the use case might be too narrow in general DS work. But if you happen to work on similar problems in similar settings, I hope this will help even if just a little bit.
References
- Codecademy Cheatsheets on SQL: https://www.codecademy.com/learn/becp-sql-for-back-end-development/modules/fscp-sql-creating-updating-and-deleting-data/cheatsheet
- Book: Django 3 By Example — Third Edition By Antonio Melé
Leave a Reply
You must be logged in to post a comment.